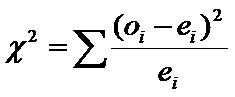Seminario 4: Explotación inferencial de base de datos.
En este seminario, el profesor nos ha enseñado como realizar las frecuencias en nuestro trabajo así como las distintos tipos de gráficas que hay. Gracias a esto, hemos podido completar los resultados de nuestro trabajo y nos ha facilitado bastante este apartado.
En primer lugar, mi grupo compuesto por Paula Álvarez Troncoso, Alcora Hernández Martín, y yo, metimos los cuestionarios en el programa de Epi Info. Una vez introducidos, accedemos al apartado "Visual Dashboard". Ahí, podemos realizar las frecuencias y distinta relaciones para realizar gráficas, tablas de frecuencia...

Aquí tenemos un ejemplo de nuestros resultados del trabajo, como podéis observar, en la primera pregunta realizamos una tabla de frecuencia para mostrar nuestros datos con sus resultados. En la segunda un diagrama de barras, y así sucesivamente con todas las distintas preguntas y sus resultados.
Me ha servido mucho este seminario y ha sido una gran ayuda. Con esto, hemos entendido mejor nuestros resultados y nos ha facilitado mucho la complejidad que tiene este trabajo.